



Researchers have developed a platform for the interactive evaluation of AI-powered chatbots such as ChatGPT.
Researchers have developed a platform for the interactive evaluation of AI-powered chatbots such as ChatGPT. A team of computer scientists, engineers, mathematicians and cognitive scientists developed an open-source evaluation platform called CheckMate, which allows human users to interact with and evaluate the performance of large language models .
Researchers have developed a platform for the interactive evaluation of AI-powered chatbots such as ChatGPT. A team of computer scientists, engineers, mathematicians and cognitive scientists, led by the University of Cambridge, developed an open-source evaluation platform called CheckMate, which allows human users to interact with and evaluate the performance of large language models . The researchers tested CheckMate in an experiment where human participants used three LLMs -- InstructGPT, ChatGPT and GPT-4 -- as assistants for solving undergraduate-level mathematics problems. The team studied how well LLMs can assist participants in solving problems. Despite a generally positive correlation between a chatbot's correctness and perceived helpfulness, the researchers also found instances where the LLMs were incorrect, but still useful for the participants. However, certain incorrect LLM outputs were thought to be correct by participants. This was most notable in LLMs optimised for chat. The researchers suggest models that communicate uncertainty, respond well to user corrections, and can provide a concise rationale for their recommendations, make better assistants. Human users of LLMs should verify their outputs carefully, given their current shortcomings., could be useful in both informing AI literacy training, and help developers improve LLMs for a wider range of uses. While LLMs are becoming increasingly powerful, they can also make mistakes and provide incorrect information, which could have negative consequences as these systems become more integrated into our everyday lives. "LLMs have become wildly popular, and evaluating their performance in a quantitative way is important, but we also need to evaluate how well these systems work with and can support people," said co-first author Albert Jiang, from Cambridge's Department of Computer Science and Technology."We don't yet have comprehensive ways of evaluating an LLM's performance when interacting with humans." The standard way to evaluate LLMs relies on static pairs of inputs and outputs, which disregards the interactive nature of chatbots, and how that changes their usefulness in different scenarios. The researchers developed CheckMate to help answer these questions, designed for but not limited to applications in mathematics. "When talking to mathematicians about LLMs, many of them fall into one of two main camps: either they think that LLMs can produce complex mathematical proofs on their own, or that LLMs are incapable of simple arithmetic," said co-first author Katie Collins from the Department of Engineering."Of course, the truth is probably somewhere in between, but we wanted to find a way of evaluating which tasks LLMs are suitable for and which they aren't." The researchers recruited 25 mathematicians, from undergraduate students to senior professors, to interact with three different LLMs and evaluate their performance using CheckMate. Participants worked through undergraduate-level mathematical theorems with the assistance of an LLM and were asked to rate each individual LLM response for correctness and helpfulness. Participants did not know which LLM they were interacting with. The researchers recorded the sorts of questions asked by participants, how participants reacted when they were presented with a fully or partially incorrect answer, whether and how they attempted to correct the LLM, or if they asked for clarification. Participants had varying levels of experience with writing effective prompts for LLMs, and this often affected the quality of responses that the LLMs provided. An example of an effective prompt is"what is the definition of X" as chatbots can be very good at retrieving concepts they know of and explaining it to the user. "One of the things we found is the surprising fallibility of these models," said Collins."Sometimes, these LLMs will be really good at higher-level mathematics, and then they'll fail at something far simpler. It shows that it's vital to think carefully about how to use LLMs effectively and appropriately." However, like the LLMs, the human participants also made mistakes. The researchers asked participants to rate how confident they were in their own ability to solve the problem they were using the LLM for. In cases where the participant was less confident in their own abilities, they were more likely to rate incorrect generations by LLM as correct. "This kind of gets to a big challenge of evaluating LLMs, because they're getting so good at generating nice, seemingly correct natural language, that it's easy to be fooled by their responses," said Jiang."It also shows that while human evaluation is useful and important, it's nuanced, and sometimes it's wrong. Anyone using an LLM, for any application, should always pay attention to the output and verify it themselves." Based on the results from CheckMate, the researchers say that newer generations of LLMs are increasingly able to collaborate helpfully and correctly with human users on undergraduate-level maths problems, as long as the user can assess the correctness of LLM-generated responses. Even if the answers may be memorised and can be found somewhere on the internet, LLMs have the advantage of being flexible in their inputs and outputs over traditional search engines . While CheckMate was tested on mathematical problems, the researchers say their platform could be adapted to a wide range of fields. In the future, this type of feedback could be incorporated into the LLMs themselves, although none of the CheckMate feedback from the current study has been fed back into the models. "These kinds of tools can help the research community to have a better understanding of the strengths and weaknesses of these models," said Collins."We wouldn't use them as tools to solve complex mathematical problems on their own, but they can be useful assistants, if the users know how to take advantage of them." The research was supported in part by the Marshall Commission, the Cambridge Trust, Peterhouse, Cambridge, The Alan Turing Institute, the European Research Council, and the Engineering and Physical Sciences Research Council , part of UK Research and Innovation .Katherine M. Collins, Albert Q. Jiang, Simon Frieder, Lionel Wong, Miri Zilka, Umang Bhatt, Thomas Lukasiewicz, Yuhuai Wu, Joshua B. Tenenbaum, William Hart, Timothy Gowers, Wenda Li, Adrian Weller, Mateja Jamnik.With generative artificial intelligence transforming the social interaction landscape in recent years, large language models , which use deep-learning algorithms to train GenAI ... A new study reveals how large language models respond to different motivational states. In their evaluation of three LLM-based generative conversational agents --ChatGPT, Google Bard, and ... The past year has seen major advances in Large Language Models such as ChatGPT. The ability of these models to interpret and produce human text sources has ... The era of artificial-intelligence chatbots that seem to understand and use language the way we humans do has begun. Under the hood, these chatbots use large language models, a particular kind of ...Public Have No Difficulty Getting to Grips With an Extra Thumb, Study Finds
Mathematics Computers And Internet Mathematical Modeling Neural Interfaces Communications Distributed Computing Computer Science
United States Latest News, United States Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
 OpenAI’s new ChatGPT privacy tool lets creators hide their work from the AIOpenAI finally announced a privacy tool for products like ChatGPT to help creators prevent their copyright content from training AI models.
OpenAI’s new ChatGPT privacy tool lets creators hide their work from the AIOpenAI finally announced a privacy tool for products like ChatGPT to help creators prevent their copyright content from training AI models.
Read more »
 30 Students Saved From Suicide By A ChatGPT Based AI, Say ResearchersInternationally known as The AI Educator. Bestselling author of 'The AI Classroom: The Ultimate Guide to Artificial Intelligence in Education.' Working with schools, universities and businesses worldwide to develop AI skills and strategy.
30 Students Saved From Suicide By A ChatGPT Based AI, Say ResearchersInternationally known as The AI Educator. Bestselling author of 'The AI Classroom: The Ultimate Guide to Artificial Intelligence in Education.' Working with schools, universities and businesses worldwide to develop AI skills and strategy.
Read more »
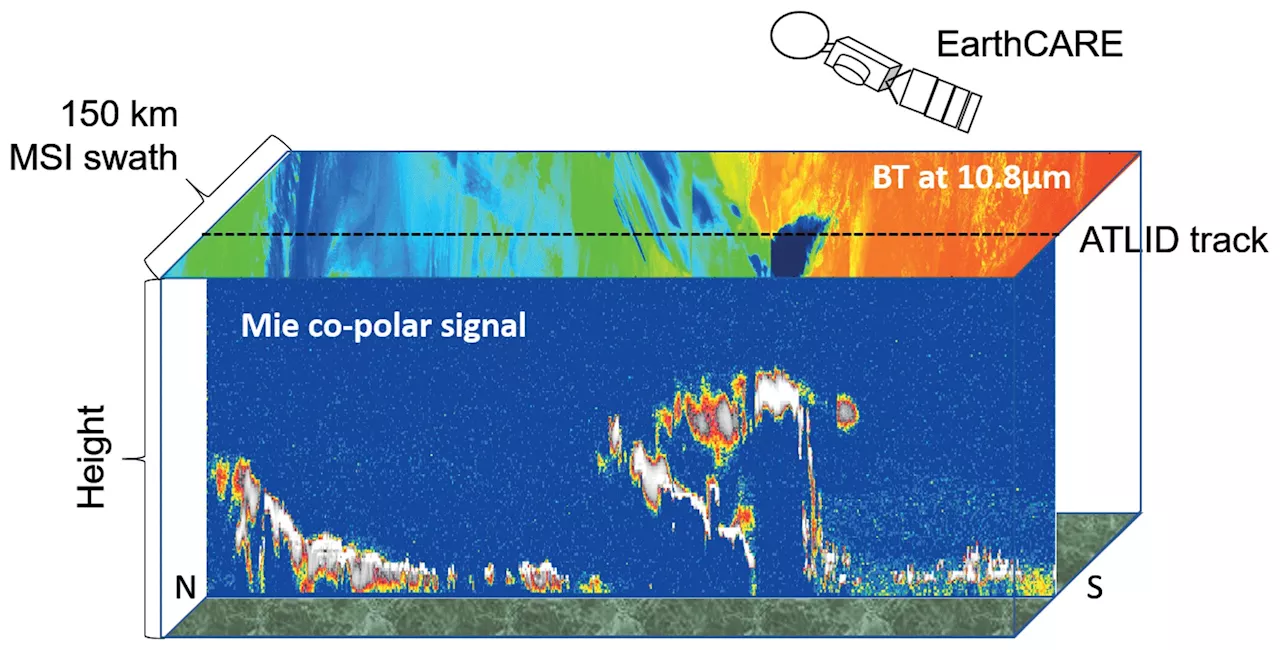 Researchers create new software for the new European-Japanese Earth observation satellite EarthCAREPreparations for the launch of the new Earth observation satellite EarthCARE (Earth Cloud Aerosol and Radiation Explorer) at the end of May are in full swing. The joint mission of the European Space Agency (ESA) and the Japan Aerospace Exploration Agency (JAXA) will measure clouds, aerosol and radiation more accurately than ever before.
Researchers create new software for the new European-Japanese Earth observation satellite EarthCAREPreparations for the launch of the new Earth observation satellite EarthCARE (Earth Cloud Aerosol and Radiation Explorer) at the end of May are in full swing. The joint mission of the European Space Agency (ESA) and the Japan Aerospace Exploration Agency (JAXA) will measure clouds, aerosol and radiation more accurately than ever before.
Read more »
 OpenAI starts training a new AI model to power ChatGPTArtificial intelligence company OpenAI said Tuesday that it has started training its newest AI model that will fuel the popular ChatGPT chatbot.
OpenAI starts training a new AI model to power ChatGPTArtificial intelligence company OpenAI said Tuesday that it has started training its newest AI model that will fuel the popular ChatGPT chatbot.
Read more »
 ChatGPT is coming to iOS 18, but ChatGPT Plus will still be betterApple's deal with OpenAI has been months in the making, with Siri reportedly running some queries on ChatGPT in iOS 18.
ChatGPT is coming to iOS 18, but ChatGPT Plus will still be betterApple's deal with OpenAI has been months in the making, with Siri reportedly running some queries on ChatGPT in iOS 18.
Read more »