
Researchers developed a more efficient way to control the outputs of a large language model, guiding it to generate text that adheres to a certain structure, like a programming language, and remains error free.
Researchers developed a more efficient way to control the outputs of a large language model, guiding it to generate text that adheres to a certain structure, like a programming language, and remains error free.
Programmers can now use large language models to generate computer code more quickly. However, this only makes programmers' lives easier if that code follows the rules of the programming language and doesn't cause a computer to crash. Some methods exist for ensuring LLMs conform to the rules of whatever language they are generating text in, but many of these methods either distort the model's intended meaning or are too time-consuming to be feasible for complex tasks. A new approach developed by researchers at MIT and elsewhere automatically guides an LLM to generate text that adheres to the rules of the relevant language, such as a particular programming language, and is also error-free. Their method allows an LLM to allocate efforts toward outputs that are most likely to be valid and accurate, while discarding unpromising outputs early in the process. This probabilistic approach boosts computational efficiency. Due to these efficiency gains, the researchers' architecture enabled small LLMs to outperform much larger models in generating accurate, properly structured outputs for several real-world use cases, including molecular biology and robotics. In the long run, this new architecture could help nonexperts control AI-generated content. For instance, it could allow businesspeople to write complex queries in SQL, a language for database manipulation, using only natural language prompts. "This work has implications beyond research. It could improve programming assistants, AI-powered data analysis, and scientific discovery tools by ensuring that AI-generated outputs remain both useful and correct," says João Loula, an MIT graduate student and co-lead author of a paper on this framework. Loula is joined on the paper by co-lead authors Benjamin LeBrun, a research assistant at the Mila-Quebec Artificial Intelligence Institute, and Li Du, a graduate student at John Hopkins University; co-senior authors Vikash Mansinghka '05, MEng '09, PhD '09, a principal research scientist and leader of the Probabilistic Computing Project in the MIT Department of Brain and Cognitive Sciences; Alexander K. Lew SM '20, an assistant professor at Yale University; Tim Vieira, a postdoc at ETH Zurich; and Timothy J. O'Donnell, an associate professor at McGill University and a Canada CIFAR AI Chair at Mila, who led the international team; as well as several others. The research will be presented at the International Conference on Learning Representations.One common approach for controlling the structured text generated by LLMs involves checking an entire output, like a block of computer code, to make sure it is valid and will run error-free. If not, the user must start again, racking up computational resources. On the other hand, a programmer could stop to check the output along the way. While this can ensure the code adheres to the programming language and is structurally valid, incrementally correcting the code may cause it to drift from the meaning the user intended, hurting its accuracy in the long run. "It is much easier to enforce structure than meaning. We can quickly check whether something is in the right programming language, but to check its meaning you have to execute the code. Our work is also about dealing with these different types of information," Loula says. The researchers' approach involves engineering knowledge into the LLM to steer it toward the most promising outputs. These outputs are more likely to follow the structural constraints defined by a user, and to have the meaning the user intends. "We are not trying to train an LLM to do this. Instead, we are engineering some knowledge that an expert would have and combining it with the LLM's knowledge, which offers a very different approach to scaling than you see in deep learning," Mansinghka adds. They accomplish this using a technique called sequential Monte Carlo, which enables parallel generation from an LLM to compete with each other. The model dynamically allocates resources to different threads of parallel computation based on how promising their output appears. Each output is given a weight that represents how likely it is to be structurally valid and semantically accurate. At each step in the computation, the model focuses on those with higher weights and throws out the rest. In a sense, it is like the LLM has an expert looking over its shoulder to ensure it makes the right choices at each step, while keeping it focused on the overall goal. The user specifies their desired structure and meaning, as well as how to check the output, then the researchers' architecture guides the LLM to do the rest. "We've worked out the hard math so that, for any kinds of constraints you'd like to incorporate, you are going to get the proper weights. In the end, you get the right answer," Loula says.To test their approach, they applied the framework to LLMs tasked with generating four types of outputs: Python code, SQL database queries, molecular structures, and plans for a robot to follow. When compared to existing approaches, the researchers' method performed more accurately while requiring less computation. In Python code generation, for instance, the researchers' architecture enabled a small, open-source model to outperform a specialized, commercial closed-source model that is more than double its size. "We are very excited that we can allow these small models to punch way above their weight," Loula says. Moving forward, the researchers want to use their technique to control larger chunks of generated text, rather than working one small piece at a time. They also want to combine their method with learning, so that as they control the outputs a model generates, it learns to be more accurate. In the long run, this project could have broader applications for non-technical users. For instance, it could be combined with systems for automated data modeling, and querying generative models of databases. The approach could also enable machine-assisted data analysis systems, where the user can converse with software that accurately models the meaning of the data and the questions asked by the user, adds Mansinghka. "One of the fundamental questions of linguistics is how the meaning of words, phrases, and sentences can be grounded in models of the world, accounting for uncertainty and vagueness in meaning and reference. LLMs, predicting likely token sequences, don't address this problem. Our paper shows that, in narrow symbolic domains, it is technically possible to map from words to distributions on grounded meanings. It's a small step towards deeper questions in cognitive science, linguistics, and artificial intelligence needed to understand how machines can communicate about the world like we do," says O'Donnell. This research is funded, in part, by the Canada CIFAR AI Chairs Program, and by the Siegel Family Foundation via gift to the MIT Siegel Family Quest for IntelligenceJoão Loula, Benjamin LeBrun, Li Du, Ben Lipkin, Clemente Pasti, Gabriel Grand, Tianyu Liu, Yahya Emara, Marjorie Freedman, Jason Eisner, Ryan Cotterell, Vikash Mansinghka, Alexander K. Lew, Tim Vieira, Timothy J. O'Donnell.In the same way that ChatGPT understands human language, a new AI model developed by computational biologists captures the language of cells to accurately predict their ... Large language models, a type of AI that analyses text, can predict the results of proposed neuroscience studies more accurately than human experts, finds a new study. The findings demonstrate that ... Researchers incorporate language ideologies, along with the impact of interaction between individuals with opposing preferences, on the language shift process. The team chose a quantitative approach ... The era of artificial-intelligence chatbots that seem to understand and use language the way we humans do has begun. Under the hood, these chatbots use large language models, a particular kind of ...
Mathematical Modeling Computer Programming Computers And Internet STEM Education Surveillance Security And Defense Educational Policy
United States Latest News, United States Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
 NASA Ames researchers working on technology to improve firefighting from the airOn Tuesday, NASA researchers performed their first wildfire test flight mission, using their new airspace management technology.
NASA Ames researchers working on technology to improve firefighting from the airOn Tuesday, NASA researchers performed their first wildfire test flight mission, using their new airspace management technology.
Read more »
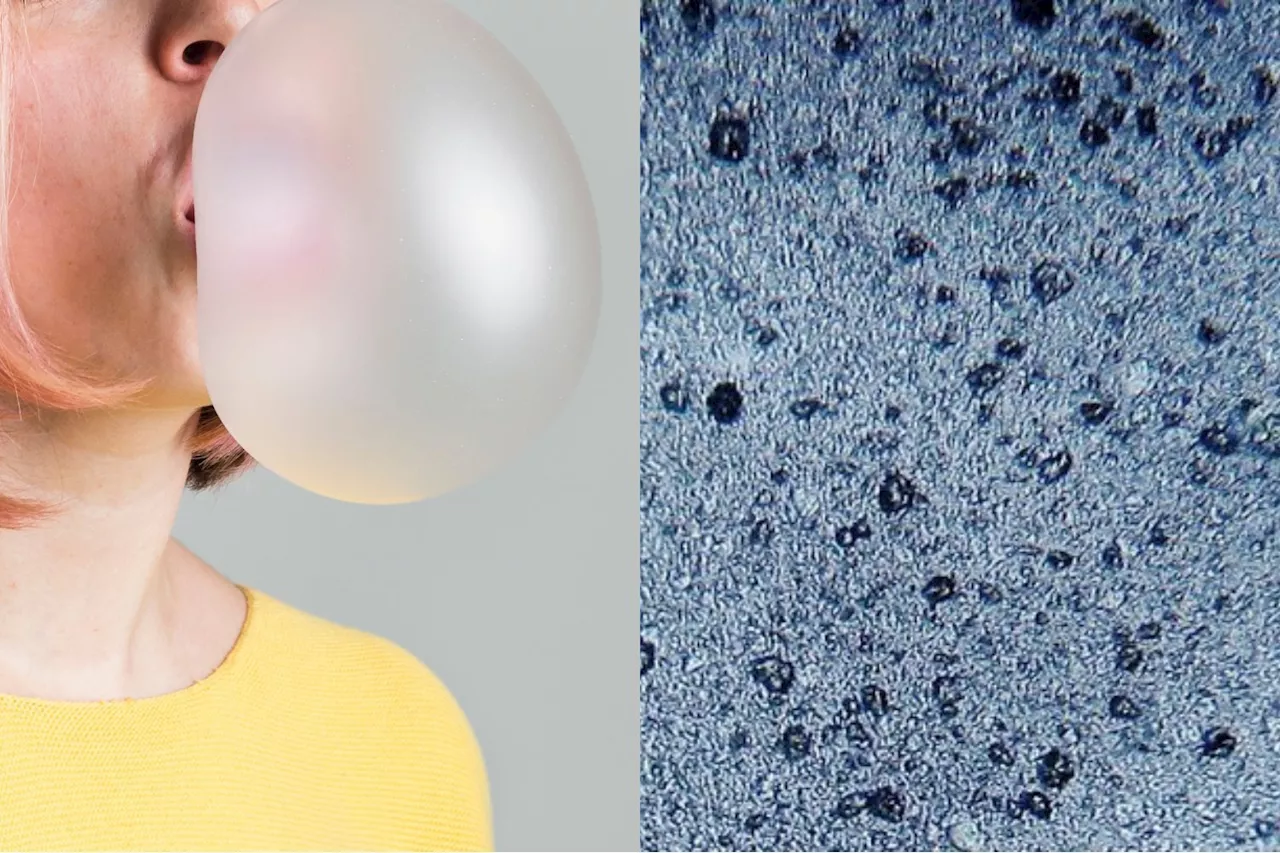 Chewing Gum Releases Thousands of Microplastics Into Our Saliva, Researchers FindResearchers tested ten different chewing gum brands, and found no difference between synthetic and natural gum.
Chewing Gum Releases Thousands of Microplastics Into Our Saliva, Researchers FindResearchers tested ten different chewing gum brands, and found no difference between synthetic and natural gum.
Read more »
 Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants.
Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants.
Read more »
 Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants. Researchers at Xijing Hospital in China say a pig kidney transplant recipient continues to recover nearly three weeks after that surgery.
Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants. Researchers at Xijing Hospital in China say a pig kidney transplant recipient continues to recover nearly three weeks after that surgery.
Read more »
 Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants.
Chinese researchers report a pig kidney transplant and a first-step liver experimentChinese researchers are reporting new steps in the quest for animal-to-human organ transplants.
Read more »
 Here's why researchers are making new psychedelic-like drugs — without the tripThis week, we've heard from researchers trying to untangle the effects of the 'trip' that often comes with psychedelics and ketamine from the ways these drugs might change the human brain. For part three of our series on psychedelic drug research, we get a glimpse into why some researchers are taking the 'trip' out of these drugs altogether.
Here's why researchers are making new psychedelic-like drugs — without the tripThis week, we've heard from researchers trying to untangle the effects of the 'trip' that often comes with psychedelics and ketamine from the ways these drugs might change the human brain. For part three of our series on psychedelic drug research, we get a glimpse into why some researchers are taking the 'trip' out of these drugs altogether.
Read more »