



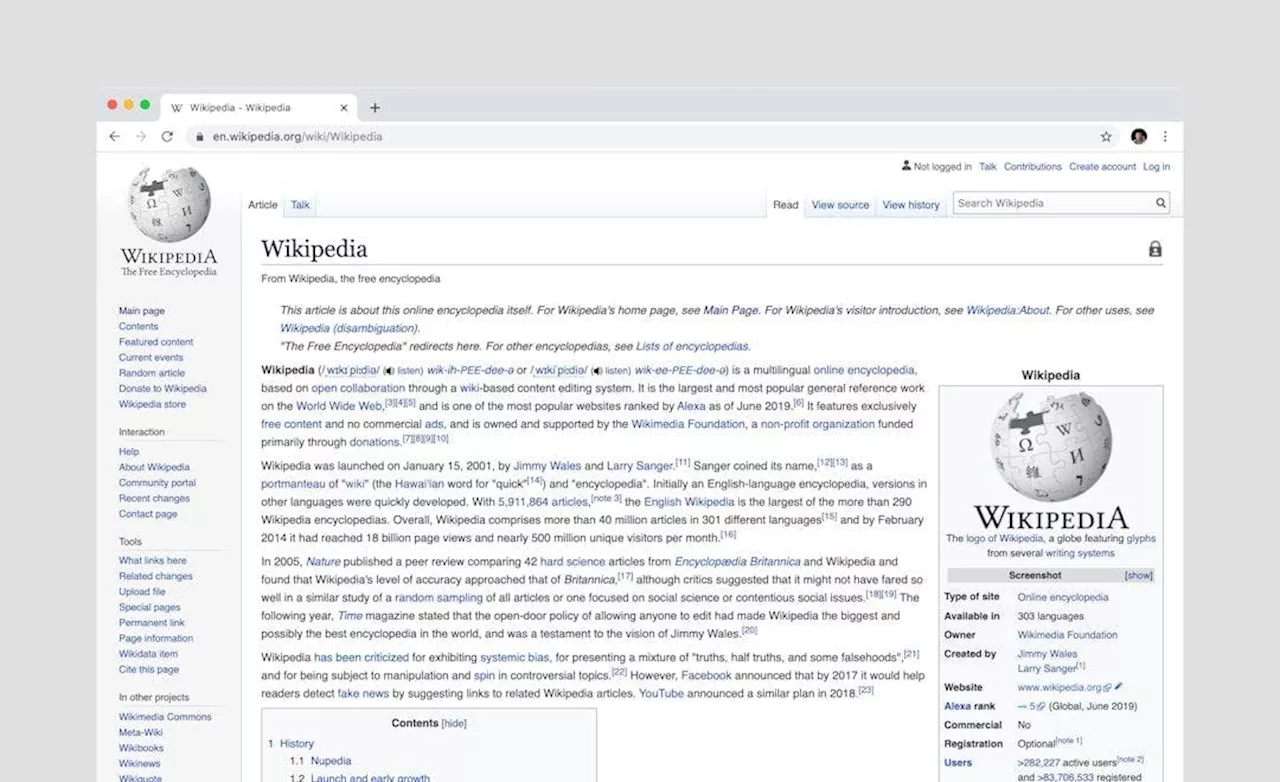
In this study, researchers exploit rich, naturally-occurring structures on Wikipedia for various NLP tasks.
Author: Mingda Chen. Table of Links Abstract Acknowledgements 1 INTRODUCTION 1.1 Overview 1.2 Contributions 2 BACKGROUND 2.1 Self-Supervised Language Pretraining 2.2 Naturally-Occurring Data Structures 2.
3 Sentence Variational Autoencoder 2.4 Summary 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.3 Summary 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4.1 Learning Entity Representations from Hyperlinks 4.2 Learning Discourse-Aware Sentence Representations from Document Structures 4.3 Learning Concept Hierarchies from Document Categories 4.4 Summary 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5.1 Disentangling Semantics and Syntax in Sentence Representations 5.2 Controllable Paraphrase Generation with a Syntactic Exemplar 5.3 Summary 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6.1 Long-Form Data-to-Text Generation 6.2 Long-Form Text Summarization 6.3 Story Generation with Constraints 6.4 Summary 7 CONCLUSION APPENDIX A - APPENDIX TO CHAPTER 3 APPENDIX B - APPENDIX TO CHAPTER 6 BIBLIOGRAPHY CHAPTER 4 - LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA In this chapter, we describe our contributions to exploiting rich, naturally-occurring structures on Wikipedia for various NLP tasks. In Section 4.1, we use hyperlinks to learn entity representations. The resultant models use contextualized representations rather than a fixed set of vectors for representing entities . In Section 4.2, we use article structures to make sentence representations aware of the broader context in which they situate, leading to improvements across various discourse-related tasks. In Section 4.3, we use article category hierarchies to learn concept hierarchies that improve model performance on textual entailment tasks. The material in this chapter is adapted from Chen et al. , Chen et al. , and Chen et al. . This paper is available on arxiv under CC 4.0 license. Author: Mingda Chen. Author: Author: Mingda Chen. Table of Links Abstract Acknowledgements 1 INTRODUCTION 1.1 Overview 1.2 Contributions 2 BACKGROUND 2.1 Self-Supervised Language Pretraining 2.2 Naturally-Occurring Data Structures 2.3 Sentence Variational Autoencoder 2.4 Summary 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.3 Summary 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4.1 Learning Entity Representations from Hyperlinks 4.2 Learning Discourse-Aware Sentence Representations from Document Structures 4.3 Learning Concept Hierarchies from Document Categories 4.4 Summary 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5.1 Disentangling Semantics and Syntax in Sentence Representations 5.2 Controllable Paraphrase Generation with a Syntactic Exemplar 5.3 Summary 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6.1 Long-Form Data-to-Text Generation 6.2 Long-Form Text Summarization 6.3 Story Generation with Constraints 6.4 Summary 7 CONCLUSION APPENDIX A - APPENDIX TO CHAPTER 3 APPENDIX B - APPENDIX TO CHAPTER 6 BIBLIOGRAPHY Abstract Abstract Abstract Acknowledgements Acknowledgements Acknowledgements 1 INTRODUCTION 1 INTRODUCTION 1 INTRODUCTION 1 INTRODUCTION 1.1 Overview 1.1 Overview 1.1 Overview 1.2 Contributions 1.2 Contributions 1.2 Contributions 2 BACKGROUND 2 BACKGROUND 2 BACKGROUND 2 BACKGROUND 2.1 Self-Supervised Language Pretraining 2.1 Self-Supervised Language Pretraining 2.1 Self-Supervised Language Pretraining 2.2 Naturally-Occurring Data Structures 2.2 Naturally-Occurring Data Structures 2.2 Naturally-Occurring Data Structures 2.3 Sentence Variational Autoencoder 2.3 Sentence Variational Autoencoder 2.3 Sentence Variational Autoencoder 2.4 Summary 2.4 Summary 2.4 Summary 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.3 Summary 3.3 Summary 3.3 Summary 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4 LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA 4.1 Learning Entity Representations from Hyperlinks 4.1 Learning Entity Representations from Hyperlinks 4.1 Learning Entity Representations from Hyperlinks 4.2 Learning Discourse-Aware Sentence Representations from Document Structures 4.2 Learning Discourse-Aware Sentence Representations from Document Structures 4.2 Learning Discourse-Aware Sentence Representations from Document Structures 4.3 Learning Concept Hierarchies from Document Categories 4.3 Learning Concept Hierarchies from Document Categories 4.3 Learning Concept Hierarchies from Document Categories 4.4 Summary 4.4 Summary 4.4 Summary 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY 5.1 Disentangling Semantics and Syntax in Sentence Representations 5.1 Disentangling Semantics and Syntax in Sentence Representations 5.1 Disentangling Semantics and Syntax in Sentence Representations 5.2 Controllable Paraphrase Generation with a Syntactic Exemplar 5.2 Controllable Paraphrase Generation with a Syntactic Exemplar 5.2 Controllable Paraphrase Generation with a Syntactic Exemplar 5.3 Summary 5.3 Summary 5.3 Summary 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6 TAILORING TEXTUAL RESOURCES FOR EVALUATION TASKS 6.1 Long-Form Data-to-Text Generation 6.1 Long-Form Data-to-Text Generation 6.1 Long-Form Data-to-Text Generation 6.2 Long-Form Text Summarization 6.2 Long-Form Text Summarization 6.2 Long-Form Text Summarization 6.3 Story Generation with Constraints 6.3 Story Generation with Constraints 6.3 Story Generation with Constraints 6.4 Summary 6.4 Summary 6.4 Summary 7 CONCLUSION 7 CONCLUSION 7 CONCLUSION 7 CONCLUSION APPENDIX A - APPENDIX TO CHAPTER 3 APPENDIX A - APPENDIX TO CHAPTER 3 APPENDIX A - APPENDIX TO CHAPTER 3 APPENDIX B - APPENDIX TO CHAPTER 6 APPENDIX B - APPENDIX TO CHAPTER 6 APPENDIX B - APPENDIX TO CHAPTER 6 BIBLIOGRAPHY BIBLIOGRAPHY BIBLIOGRAPHY CHAPTER 4 - LEARNING SEMANTIC KNOWLEDGE FROM WIKIPEDIA In this chapter, we describe our contributions to exploiting rich, naturally-occurring structures on Wikipedia for various NLP tasks. In Section 4.1, we use hyperlinks to learn entity representations. The resultant models use contextualized representations rather than a fixed set of vectors for representing entities . In Section 4.2, we use article structures to make sentence representations aware of the broader context in which they situate, leading to improvements across various discourse-related tasks. In Section 4.3, we use article category hierarchies to learn concept hierarchies that improve model performance on textual entailment tasks. The material in this chapter is adapted from Chen et al. , Chen et al. , and Chen et al. . This paper is available on arxiv under CC 4.0 license. This paper is available on arxiv under CC 4.0 license. available on arxiv
United States Latest News, United States Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
 How To Respond To The Shifting Tides Of Leveraging Customer DataMichael Benedek is CEO of Datonics, an online data company and pioneer in the integration of audience data into programmatic platforms. Read Michael Benedek's full executive profile here.
How To Respond To The Shifting Tides Of Leveraging Customer DataMichael Benedek is CEO of Datonics, an online data company and pioneer in the integration of audience data into programmatic platforms. Read Michael Benedek's full executive profile here.
Read more »
 Three Keys For Effectively Leveraging GenAI To Optimize Knowledge BasesRohan Joshi is the CEO and co-founder of Wolken Software, a leading IT service management and customer service desk software provider. Read Rohan Joshi's full executive profile here.
Three Keys For Effectively Leveraging GenAI To Optimize Knowledge BasesRohan Joshi is the CEO and co-founder of Wolken Software, a leading IT service management and customer service desk software provider. Read Rohan Joshi's full executive profile here.
Read more »
 Leveraging Lessons From Next-Gen Social: Enterprise Strategies for User-Centric AI DeploymentSocial media platforms like Lips, Landing, and Diem are addressing AI challenges in data privacy and bias through user-centric data annotation and ethical AI.
Leveraging Lessons From Next-Gen Social: Enterprise Strategies for User-Centric AI DeploymentSocial media platforms like Lips, Landing, and Diem are addressing AI challenges in data privacy and bias through user-centric data annotation and ethical AI.
Read more »
 Leveraging Natural Supervision for Language Representation: Sentence Variational AutoencoderIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Leveraging Natural Supervision for Language Representation: Sentence Variational AutoencoderIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Read more »
 Leveraging Natural Supervision for Language Representation Learning and Generation: AbstractIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Leveraging Natural Supervision for Language Representation Learning and Generation: AbstractIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Read more »
 Leveraging Natural Supervision for Language Representation Learning and Generation: AcknowledgementsIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Leveraging Natural Supervision for Language Representation Learning and Generation: AcknowledgementsIn this study, researchers describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision.
Read more »